In-place pod resize on Kubernetes 1.33+. When running on Kubernetes 1.33
or later, Thoras applies CPU and memory adjustments without restarting pods,
eliminating the rollout churn historically required by vertical autoscalers.
Thoras falls back to a rolling restart automatically on older clusters or
when an in-place resize is not supported (for example, a QoS class change).
See Update Policy for details.
Prerequisites
Before you begin, make sure:- Thoras is installed and running in your Kubernetes cluster.
- The Kubernetes Metrics Server is installed in your cluster.
- Your workloads are instrumented with resource requests and have some usage history.
Sample Configuration
Here’s an exampleAIScaleTarget that configures rightsizing.
ast.yaml
Vertical Breakdown
spec.vertical.modeset torecommendationensures Thoras suggests optimal requests and limits but does not apply them.spec.vertical.containers[].nameshould be set to the name of the container in the pods for the workload you are targeting with thisAIScaleTarget. This field supports wildcard patterns (e.g.,app-*,*-sidecar) to match multiple containers. See Container Name Wildcard Matching for details.spec.vertical.containers[].RESOURCE.lowerboundis the lowest Thoras is allowed to set the request for that resource and is a required field.spec.vertical.containers[].RESOURCE.upperboundis the highest Thoras is allowed to set the request for that resource and is an optional field.spec.vertical.containers[].RESOURCE.limitallows thoras to modify the container’s limit along with the request for this resource and is optional. If unset, Thoras will not modify limits for this resource.spec.vertical.containers[].RESOURCE.limit.ratiothe ratio used to keep the limit inline with the suggested request for this resource. E.g. for a ratio2.5Thoras will make the limit2.5Gif the suggestion for the request was for1G.
How Limits Work With Predictive Right-Sizing
When Thoras right-sizes your pods, it respects existing resource limits to ensure safe operation. Here’s how limits interact with Thoras recommendations:Limit Enforcement Rules
Thoras enforces the following maximum constraints when right-sizing:- AIScaleTarget
upperbound: If you define anupperboundin your AIScaleTarget, Thoras will never set requests to above that value during steady-state operation. - Pod spec
limit: If alimitexists on the pod spec, Thoras will never right-size a pod above that limit during steady-state operation.
limit and an AIScaleTarget upperbound are set, Thoras uses
the lower of the two as the effective maximum value for right-sizing.
upperbound is a steady-state constraint. The one exception is
OOM remediation, an opt-in emergency response that
intentionally bypasses memory.upperbound so it can lift a workload out of an
out-of-memory kill loop. Steady-state recommendations are clamped to
upperbound as usual once the remediation’s stabilization window expires.
Scaling Limits Proportionally
You can configure Thoras to automatically scale your resource limits along with your requests using thelimit.ratio setting. This keeps limits proportional to
requests as Thoras adjusts resource allocations.
For example, setting .spec.vertical.containers[].RESOURCE.limit.ratio: 1.5
means that if Thoras recommends a request of 1G, the limit will be set to
1.5G.
See the
AIScaleTarget reference documentation for
more details on configuring the limit.ratio field.
Update Policy
Theupdate_policy field controls pod update behavior during vertical scaling
operations (such as restarts).
Configuration:
update_mode- Determines how pod updates are applied:recreate- Pods are recreated when resource changes are appliedin_place- Changes applied without pod recreation (requires Kubernetes 1.33+)in_place_or_recreate- Attempts in-place updates with fallback to recreation (recommended)initial- Recommendations apply only during pod creation
recreate_resources(optional; defaults tomemoryonly) - Array specifying which resources (memory,cpu) trigger pod recreation when using recreate or fallback modes.
memory or cpu
require right sizing:
Note: Enabling in-place resizing does not guarantee that pods will never restart during resizing operations. Pods may still be evicted and restarted if the resize would change the pod’s QoS class or if the cluster does not support the specific resize operation.How it works:
- When
update_modeisin_placeorin_place_or_recreate, Thoras attempts to resize pods in place using the Kubernetes resize API - When
update_modeisin_place_or_recreateand the pods QoS class would change or resize is not supported, Thoras falls back to recreating the pod - Evicted pods are rolled out gradually to minimize service disruption
- Reduced disruption: Pods continue running during resource adjustments
- Faster scaling: Changes take effect immediately without pod recreation
- Better node utilization: Enables more efficient bin-packing and cost savings, especially when combined with node autoscaling tools like Karpenter
- Graceful fallback: Automatic eviction when in-place resizing isn’t possible
- Fine-grained control: Specify which resources trigger pod recreation
- Kubernetes 1.33+
Additional Details
- Thoras recommendations are based on historical usage data collected from the Kubernetes Metrics Server.
- Recommendations are updated on the interval defined by
spec.model.forecast_interval. - If resource usage patterns change significantly, Thoras will adjust its suggestions accordingly.
- You can monitor the impact of rightsizing by reviewing resource utilization and cost metrics in the Thoras Dashboard.
- For workloads with multiple containers, you can specify vertical settings for
each container individually under
spec.vertical.containers. spec.vertical.containers[].RESOURCEcan be eithercpuormemory. If either is unset for a container, Thoras will not scale that resource for that container.
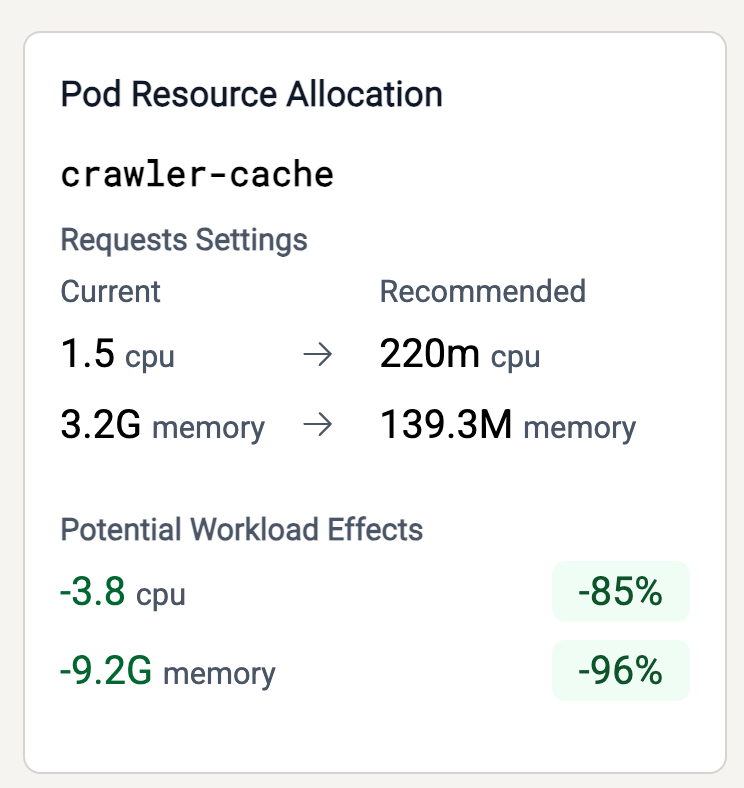
Viewing Recommendations
Once theAIScaleTarget is applied, The Thoras Reasoning Engine will begin
analyzing resource usage and generate vertical sizing recommendations on the
interval defined by spec.model.forecast_interval.
You can view the suggested requests and their projected effects on your workload
in the Thoras dashboard under Resource Allocation Settings.
Next Steps
- Change
spec.vertical.modetoautonomousif you want Thoras to automatically apply recommendations. - Add optional
scaling_behaviorif you want to fine-tune the thresholds Thoras uses to determine if a recommendation is worth restarting the entire workload.
ast.yaml
Autonomous Mode
The Thoras Reasoning Engine will make usage predictions on the interval set byspec.model.forecast_interval for the length of spec.model.forecast_blocks. If no
spec.vertical.scaling_behavior is set then Thoras will check all resource
requests to determine if they match the current suggestion. If any resource
request differs from the current suggestion, Thoras triggers a rollout restart
of the workload. As the pods restart, their resource requests and limits will be
updated to match the suggestion made by Thoras.
Note: Thoras mutates the resource requests and limits of running pods directly. It does not modify the Deployment or StatefulSet object itself.
Note: Only one scaling direction (horizontal or vertical) can be in
autonomous mode at a time. See
Configuring AIScaleTargets
for additional details.